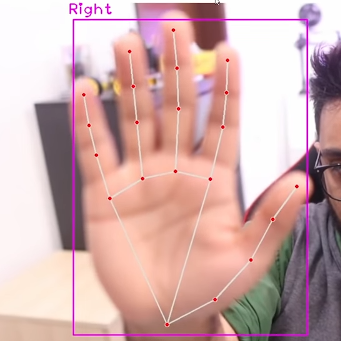
Computer vision enables robots to perceive their surrounding similar to how us humans do.
Common processes in computer vision is locating, tracking and classifying objects in videos. It’s also possible to estimate depth information of individual objects or even all pixels in an image, or to estimate the motion of the camera. Classical use cases for computer vision include:
- Automatic visual inspection in agriculture (detecting disease, malnutrition, dehydration or ripeness)
- Detecting objects on conveyor belts for packing on pallets
- In healthcare for automatic x-ray/CT/MRI analysis and diagnostics
- Detecting defects in manufacturing
At Dyno Robotics we are especially exited about the capabilities that computer vision brings to mobile robots such as:
- Visual odometry and localization of the robot using its cameras
- Object and surface detection for collision avoidance in autonomous navigation
- Detecting humans and their facial expressions and intentions for natural interaction
- Automatic visual inspection by power plants, factories, farms etc by mobile robots
At its core, for us computer vision is about having robots understanding their surroundings, giving them as much knowledge as possible about the situation in order to make smarter decisions.

Computer vision in your business
We can help you create awesome solutions for your business using computer vision. We’ll handle all of the complexities and create great software for your business and your customers – no matter the size of you organization or the industry you’re operating in.
Technological framework
Computer vision can refer to many separate things, and depending on the problem you are trying to solve there are different techniques that can be applied to best solve them. In the late 1960s, computer vision began at universities which were pioneering artificial intelligence. Studies in the 1970s formed the early foundations for many of the methods that exists today, such as extraction of edges from images, optical flow and motion estimation.
In the 1990s some of the previous research topics became more active than the others. Research in projective 3D reconstructions led to better understanding of camera calibration. It was realized that a lot of ideas were already explored in bundle adjustment theory from the field of photogrammetry. This led to methods for sparse 3D reconstruction of scenes from multiple images, and later dense stereo depth correspondence techniques. Image segmentation problems where often solved with variations of the graph cut energy minimization optimization.
Towards the end of the 1090s we saw and increased interaction between the fields of computer graphics and computer vision. This included image-based rendering, image morphing, view interpolation, panoramic image stitching and light-field rendering.
From 2010 and onward, the computer vision field saw and explosion in the use of neural networks to solve problems. This was a mayor revolution in the field and led to much greater accuracy and better results for many of the problems that we are trying to solve with computer vision. The release of the massive ImageNet dataset in 2009 opened up new possibilities for researchers to innovate in applying neural networks training to solve computer vision problems.

Deep Neural Network
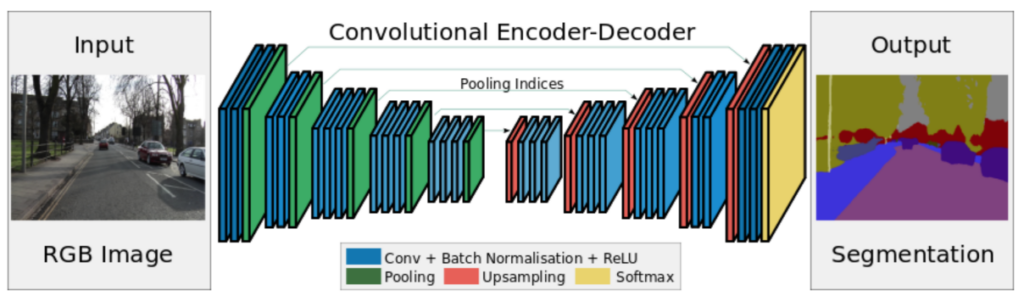
For image classification (labeling an image based on its content) popular neural network architectures include AlexNet (8 layers), VGG (19 layers) and ResNet (152 layers). If you want to label individual pixels in an image (so called image segmentation) we can use the Segnet, FCN+CRF or U-Net.
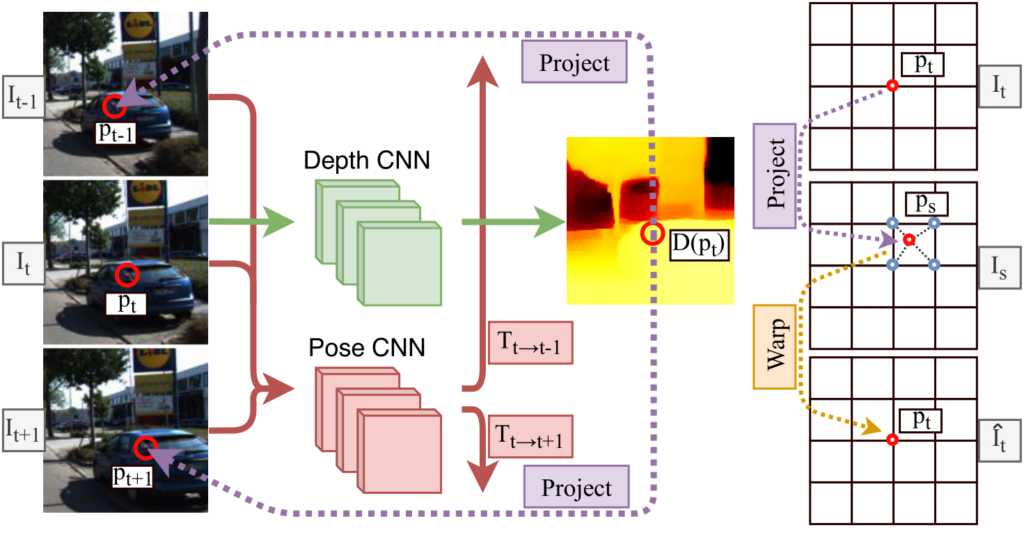
For depth and camera motion estimation we have used the MonoDepth2 architecture.
The most two popular programming frameworks for designing and training neural networks are Tensorflow and PyTorch. At Dyno Robotics we work with both of these frameworks.
OpenCV
One of the largest computer vision frameworks is OpenCV. It was initially an Intel Reasearch initiative to advance CPU-intensive applications. Starting with 2011 OpenCV also features GPU accelerated algorithms, and they have also been adding neural networks to the framework lately. But it is most famous for being a toolbox of more traditional computer vision techniques. It includes algorithms for ego motion estimation, facial and gesture recognition, object detection, segmentation, stereopsis, structure from motion and motion tracking.